K-Fold Cross-Validation: A Score You Can Trust
What you'll build
Replace tutorial 72's single train/test split with 5-fold cross-validation - train five times, test on every game exactly once - to get a stable accuracy estimate (67.8%) and, just as important, its spread across folds.
In the train/test tutorial we held out 25% of the games, scored the home-win classifier on them, and got 67.9%. Honest — but which 25%? Shuffle differently and that number jumps around, because a single test set is itself a small, lucky (or unlucky) sample. K-fold cross-validation fixes that: split the games into k folds, train k times — each time holding out a different fold to test on — and average. Every game gets tested exactly once, so you get a more stable score and a measure of how much it wobbles.
We reuse the tutorial-71 logistic regression and the bundled nba_ratings.csv + nba_home_results.csv, in pure numpy, offline.
Go deeper with the free textbook: Chapter 30: The Machine Learning Workflow at DataField.dev.
-
Split the games into k folds
Shuffle once with a fixed seed, then chop the shuffled indices into k roughly-equal folds. Each fold will take a turn as the test set.
python import numpy as np # ... build x_all (net-rating gap) and y_all (home win) as in tutorial 71 ... K = 5 rng = np.random.default_rng(73) idx = rng.permutation(len(x_all)) # shuffle once folds = np.array_split(idx, K) # K roughly-equal index foldsThat's the entire setup. The trick is in how we loop over the folds next.
-
Train k times, each holding out one fold
For each fold
i, the test set is foldiand the training set is everything else. We reuse the exact logistic-regression training from tutorials 71–72.python def sigmoid(z): return 1.0 / (1.0 + np.exp(-z)) def train_and_score(x_tr, y_tr, x_te, y_te): w, b, lr = 0.0, 0.0, 0.3 for _ in range(400): p = sigmoid(w*x_tr + b) err = p - y_tr w -= lr*np.mean(err*x_tr); b -= lr*np.mean(err) return float(((sigmoid(w*x_te + b) >= 0.5) == y_te).mean()) scores = [] for i in range(K): test_idx = folds[i] train_idx = np.concatenate([folds[j] for j in range(K) if j != i]) scores.append(train_and_score(x_all[train_idx], y_all[train_idx], x_all[test_idx], y_all[test_idx]))The key line is the
train_idx: it stitches together the four folds that aren't the test fold. Five iterations, five independent test scores, and every game has been a test game exactly once. -
Read the spread, not just the average
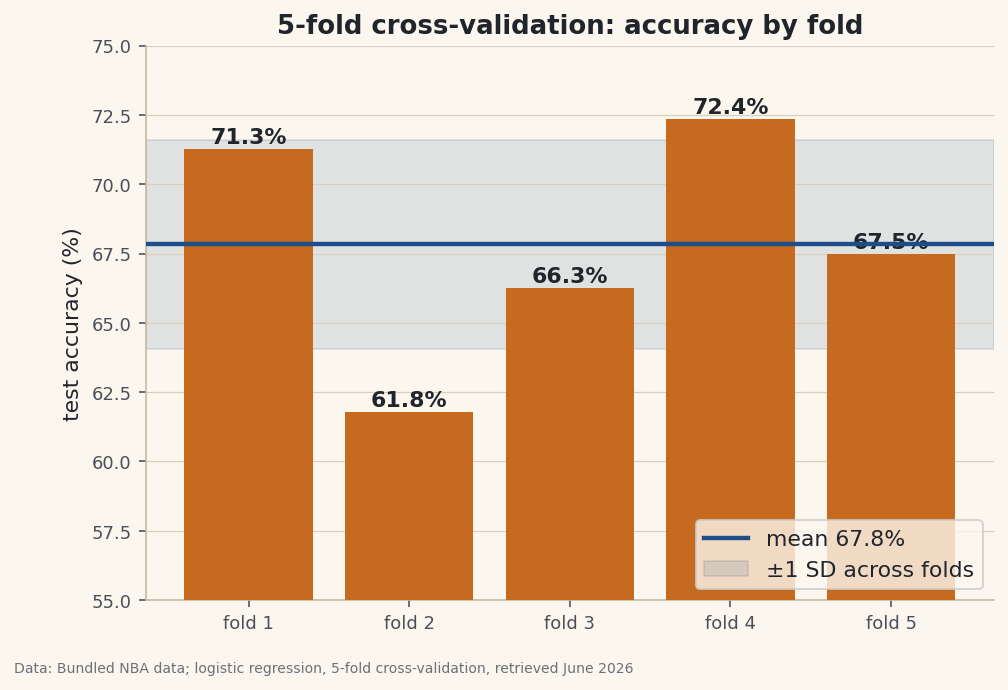
5-fold cross-validation5-fold cross-validation (each game tested exactly once): fold 1: 71.3% (test n=247) fold 2: 61.8% (test n=246) fold 3: 66.3% (test n=246) fold 4: 72.4% (test n=246) fold 5: 67.5% (test n=246) Mean accuracy: 67.8% Std across folds: 3.8 points -> about 64.1% to 71.6% A single split could have reported anywhere in that range by luck of the draw.
Data: Bundled Basketball-Reference net ratings + 1,231 game results, 5-fold cross-validation, retrieved June 2026 This is the payoff. The five folds range from 61.8% to 72.4% — a 10-point spread — and average 67.8%. The single split in tutorial 72 happened to land at 67.9%, right on the mean, but it just as easily could have reported 62% or 72% depending on the shuffle. Cross-validation gives you the stable middle and tells you the honest uncertainty: this model is about 68% accurate, give or take ~4 points.
-
Why this is the standard
Reporting a single test number invites two mistakes: bragging about a lucky high split, or panicking over an unlucky low one. The mean of k folds is a far less biased estimate of how the model will do on new data, and the spread across folds is a free uncertainty estimate — no extra data required. That's why “5-fold CV accuracy = 67.8% ± 3.8” is how practitioners actually report a model, rather than “67.9% on my test set.” More folds (k=10) give a slightly more stable mean at more compute; k=5 is the common sweet spot.
Troubleshooting
My folds are wildly different sizes
If your data length isn't divisible by k, np.array_split handles it gracefully (some folds get one extra row). Avoid plain np.split, which errors on uneven splits. The tiny size difference doesn't matter.
One fold's score is far off the others
On small folds (~245 games) a few points of swing is normal sampling noise — that's exactly what cross-validation is revealing. If one fold is wildly off, check that you shuffled before splitting; unshuffled data with any time or team ordering can create a lopsided fold.
Should I retrain or reuse the model across folds?
Retrain from scratch every fold — that's the whole point. Reusing weights leaks information from a fold's test games into its training and inflates the score. Each fold must be trained only on its own four training folds.
Challenge yourself
Try k = 10 and watch the mean barely move while the per-fold spread changes — then push to leave-one-out (k = number of games) and see how expensive it gets. Next, wrap the whole thing in a function and use it to compare two models (one feature vs. two) on the same folds — the fair way to decide if a feature actually helps. Finally, add stratification: make each fold preserve the overall home-win rate, which steadies the estimate further on imbalanced data.
Get the code
Here's the complete, working script for this tutorial. It runs exactly as shown.
Download the finished script (73_kfold_cross_validation.py)This script imports a small shared helper (and reads any bundled sample data) that live next to it in /downloads/ — grab these into the same folder so it runs as-is: sdt_common.py, sdt_nba.py.