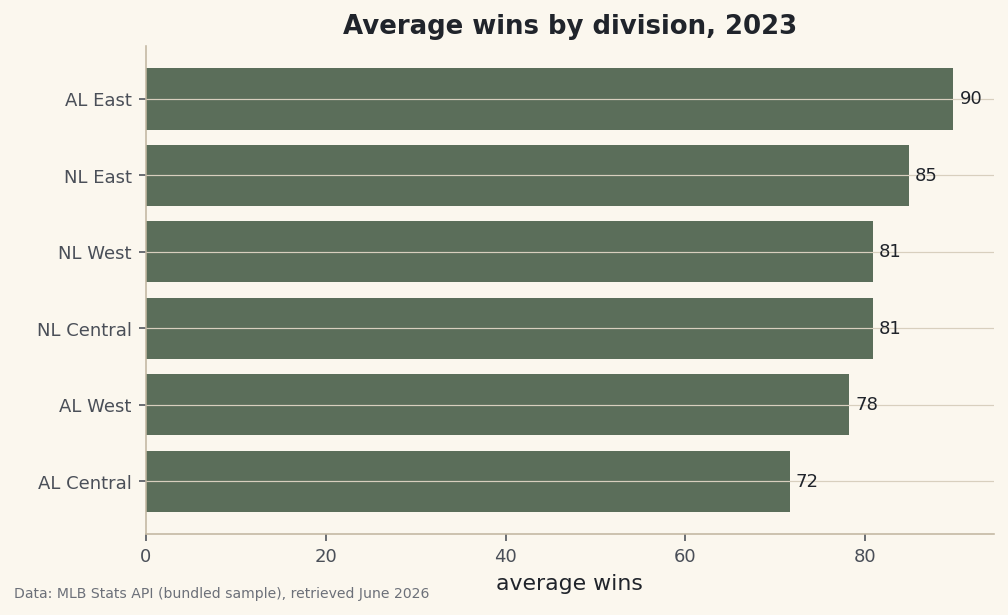
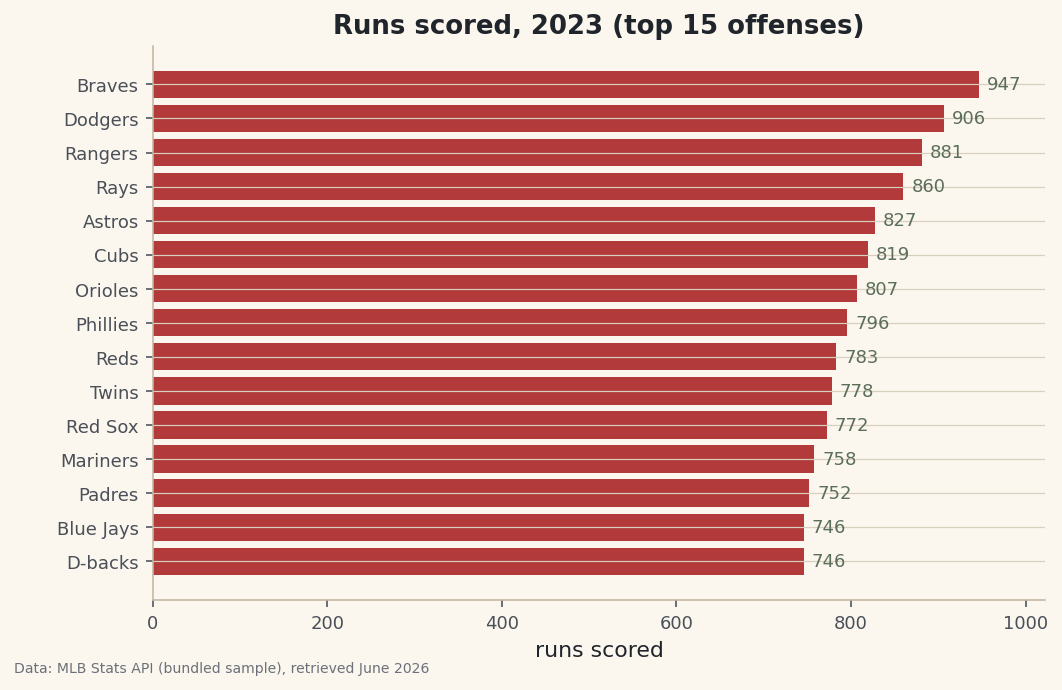
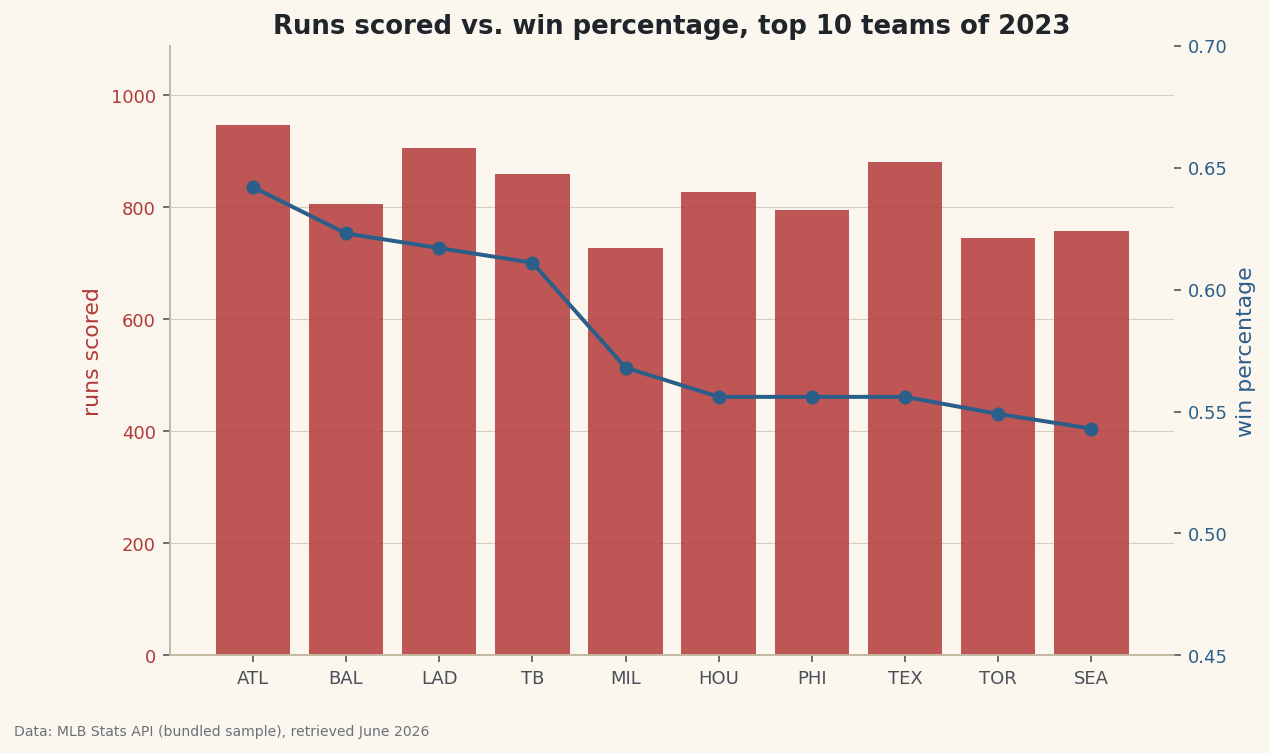
Sport-agnostic skills - Python, pandas, plotting and data cleaning - that every other tutorial builds on.
If you're new, run the Python setup tutorial first, then the twelve-operation pandas tour and the grouping-and-pivoting tutorial; every sport track assumes them. The statistics tutorials — summary stats and distributions, correlation and regression, z-scores — slot in whenever a sport tutorial leans on a concept you haven't met. Everything runs on bundled real data, in your browser if you like — no installs required to follow along.
Install Python, a code editor, and the core data libraries the right way, then prove your setup works by running a tiny script that imports pandas and matplotlib.
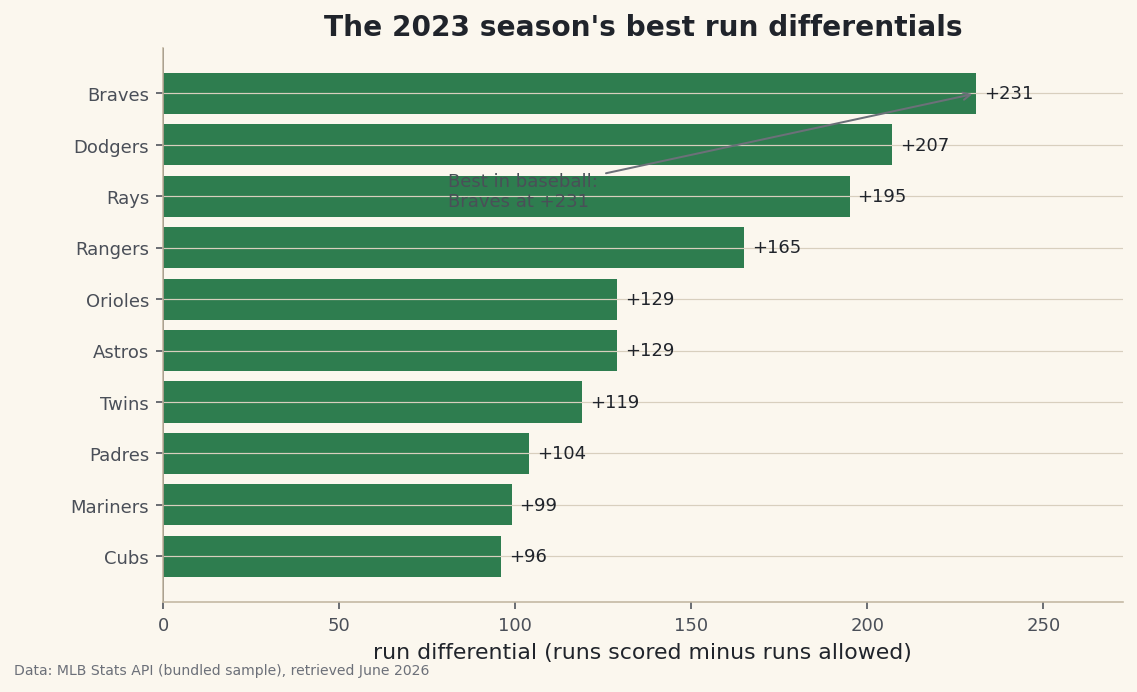
Go from a DataFrame to a clean, labeled bar chart with matplotlib. Learn the figure/axes model, titles, and how to save a chart you'd actually publish.
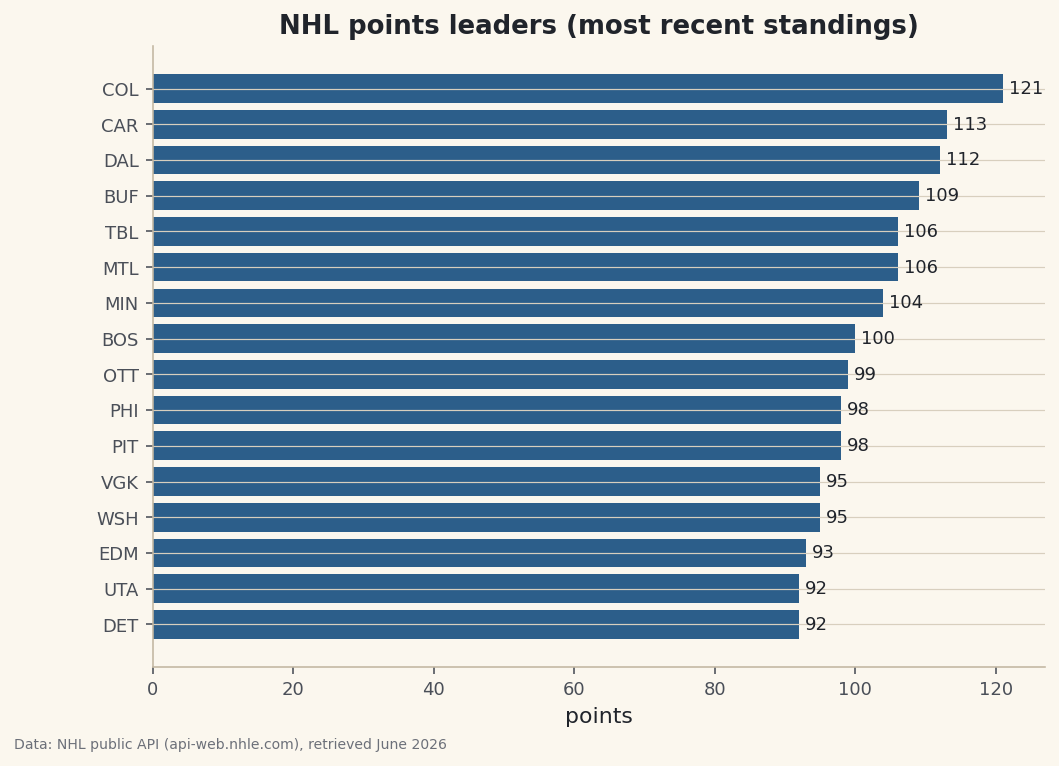
Endpoints, parameters, JSON, status codes - learn to read API docs by pulling live standings from the public NHL API and shaping the response into a DataFrame.
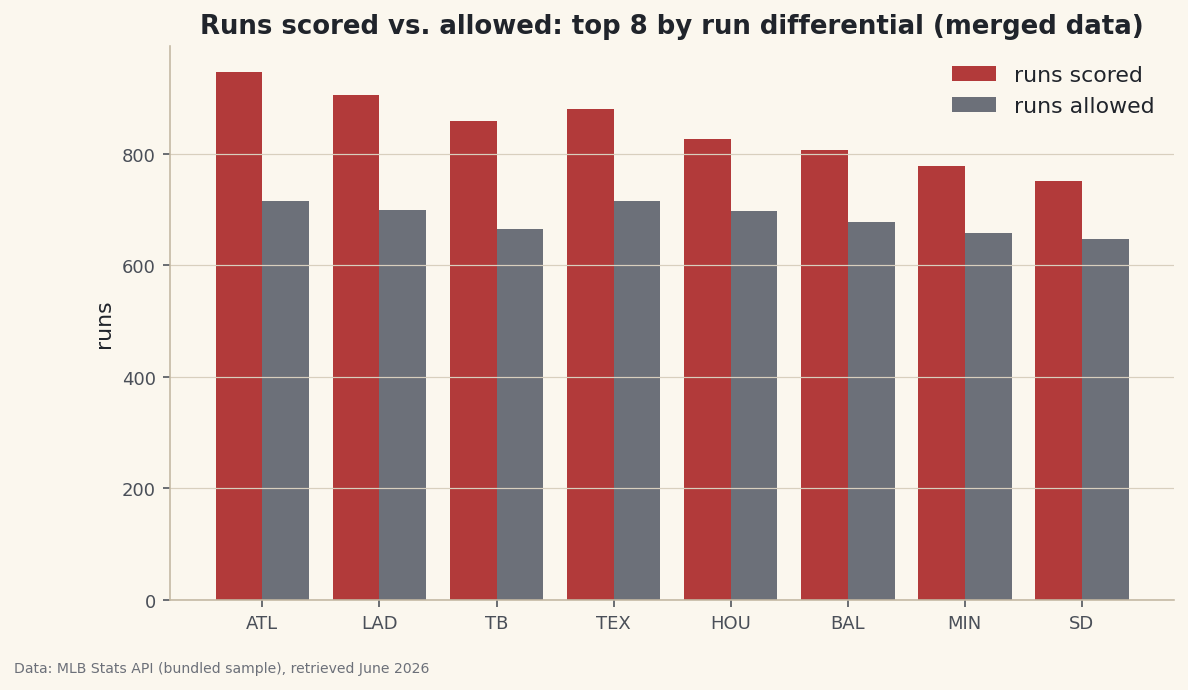
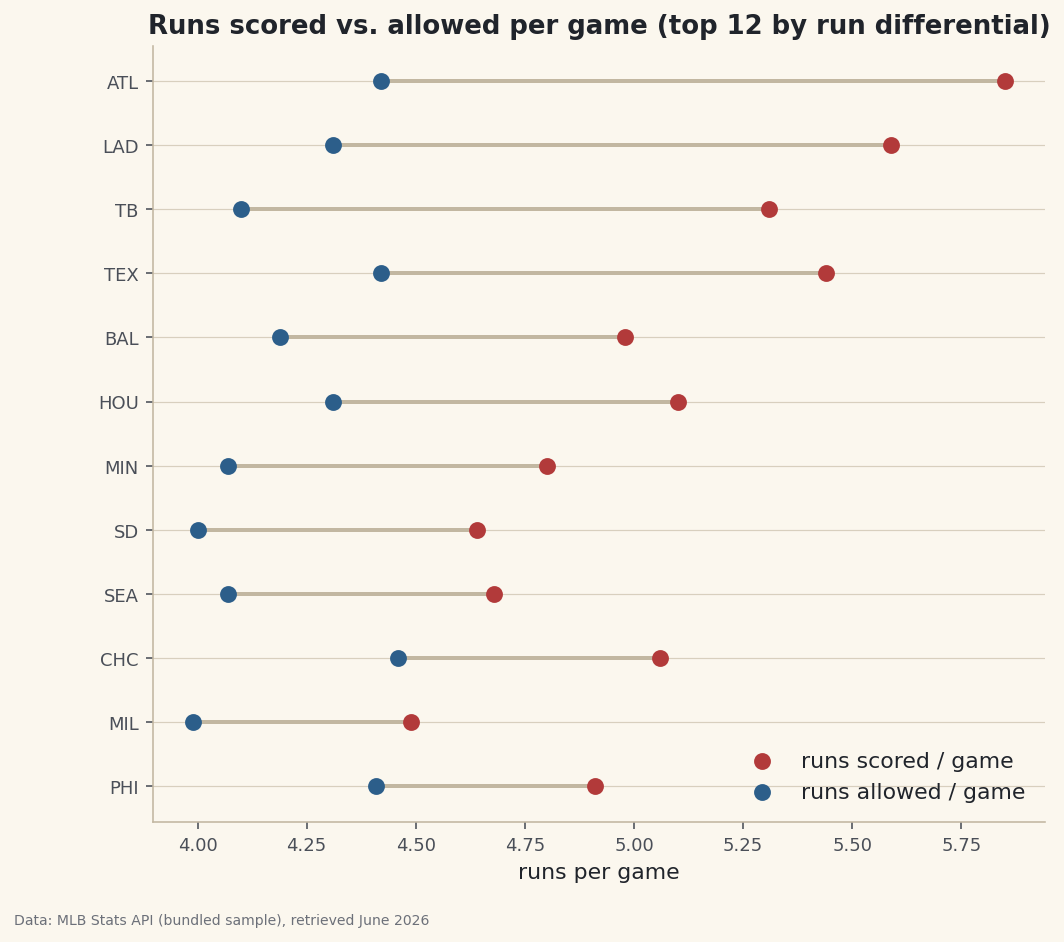
Combine a record table and a scoring table on a shared key with pandas merge, choose the right join type, and chart a column that lived in neither alone.
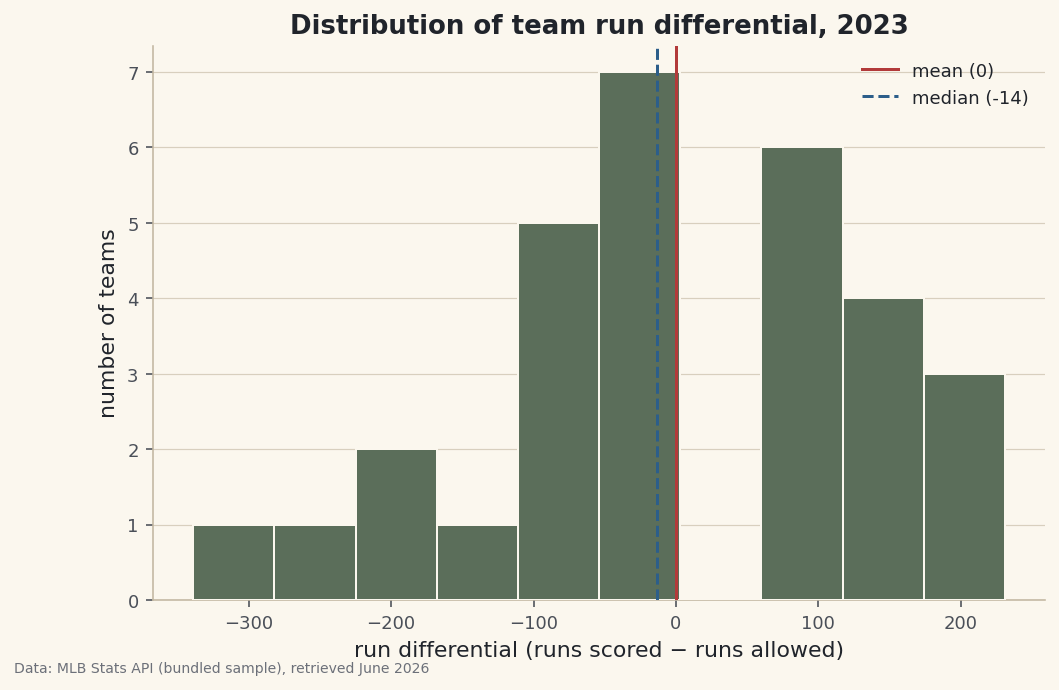
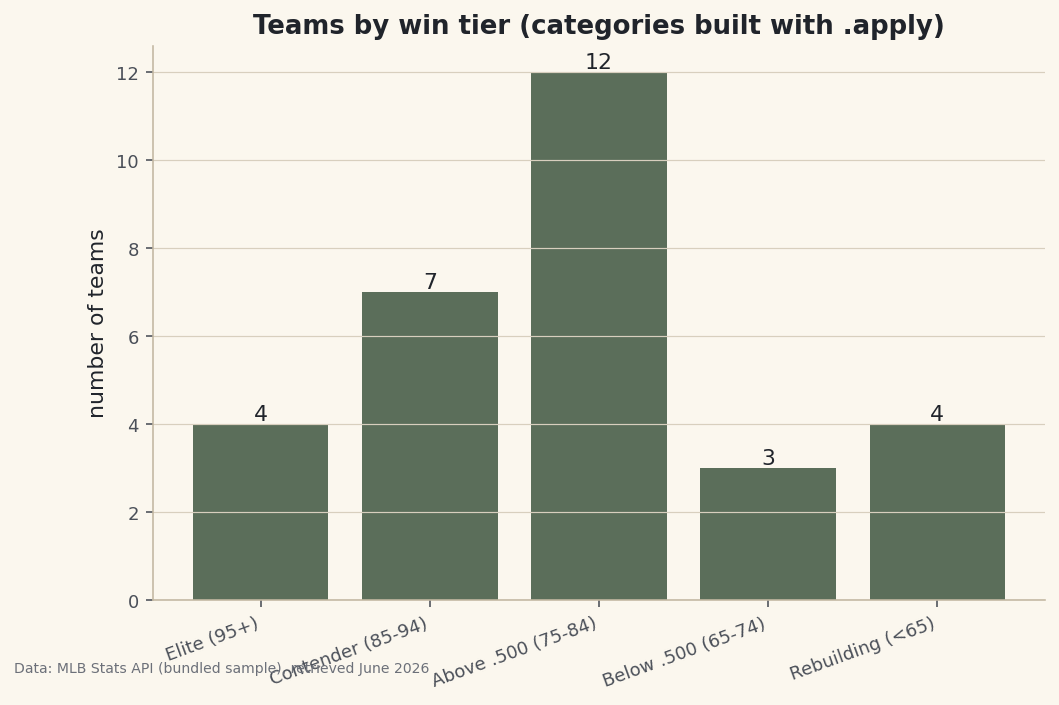
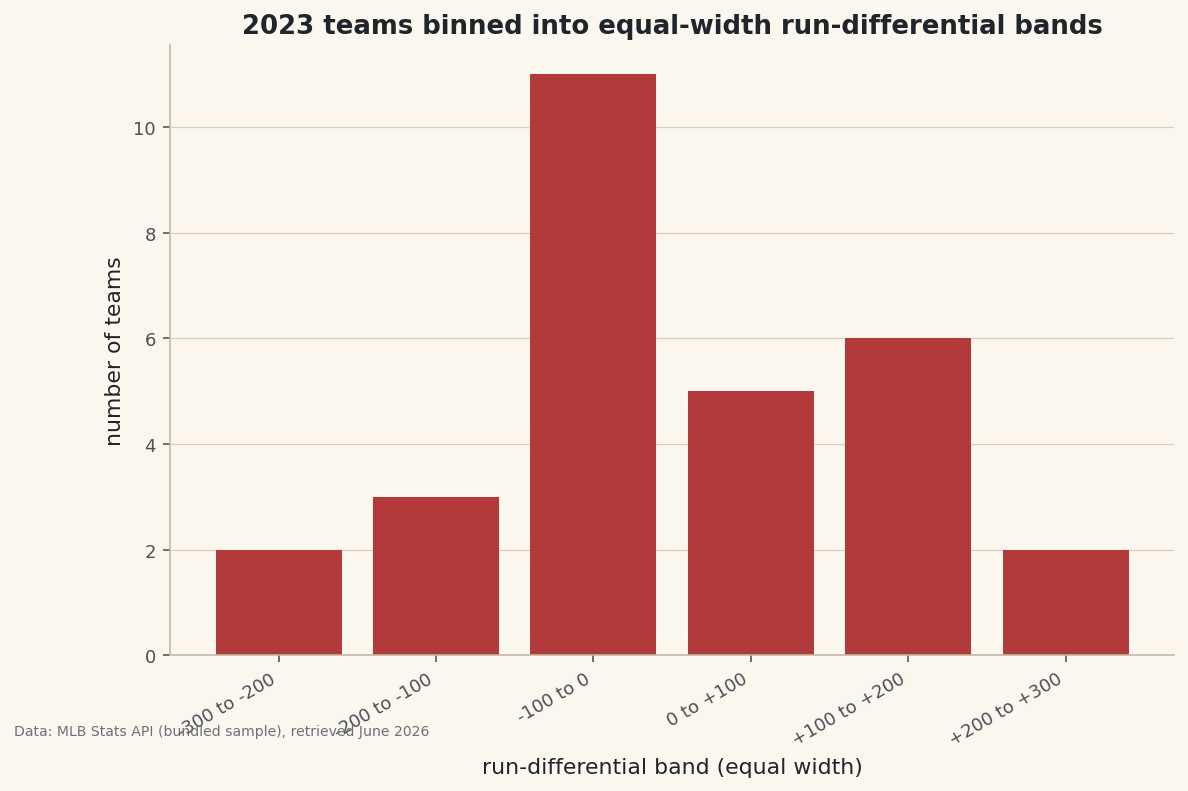
pd.cut() slices a continuous column into fixed-width bands you define — the companion to qcut() — turning raw run differential into labeled tiers, charted.
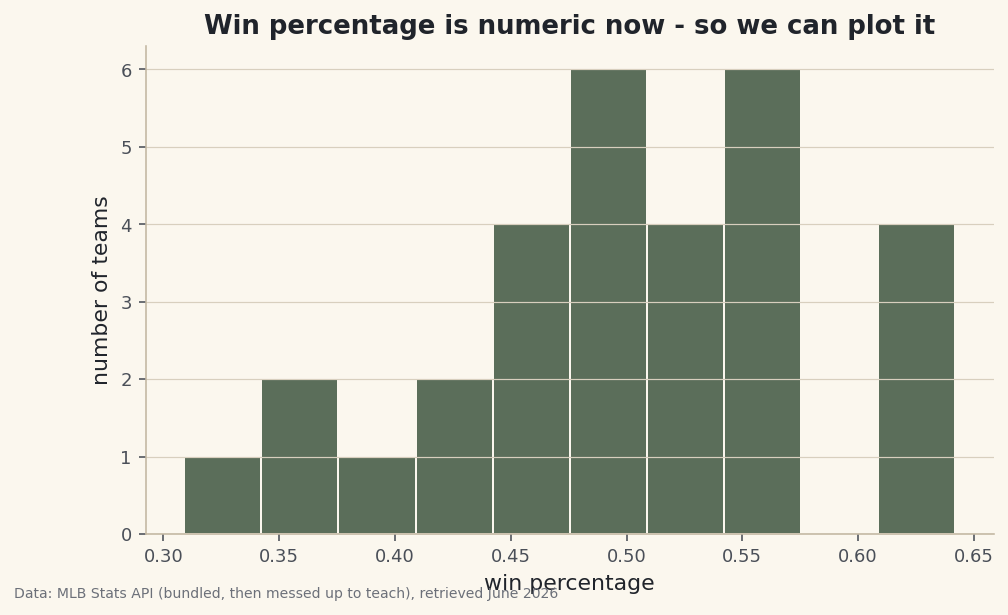
Mixed types, stray whitespace, duplicate rows, percent signs in numbers - fix the data problems that derail real sports projects, with before-and-after proof.
Go beyond groupby: build pivot tables, reshape between wide and long with melt and stack, and turn raw rows into the summary tables analysts actually present.
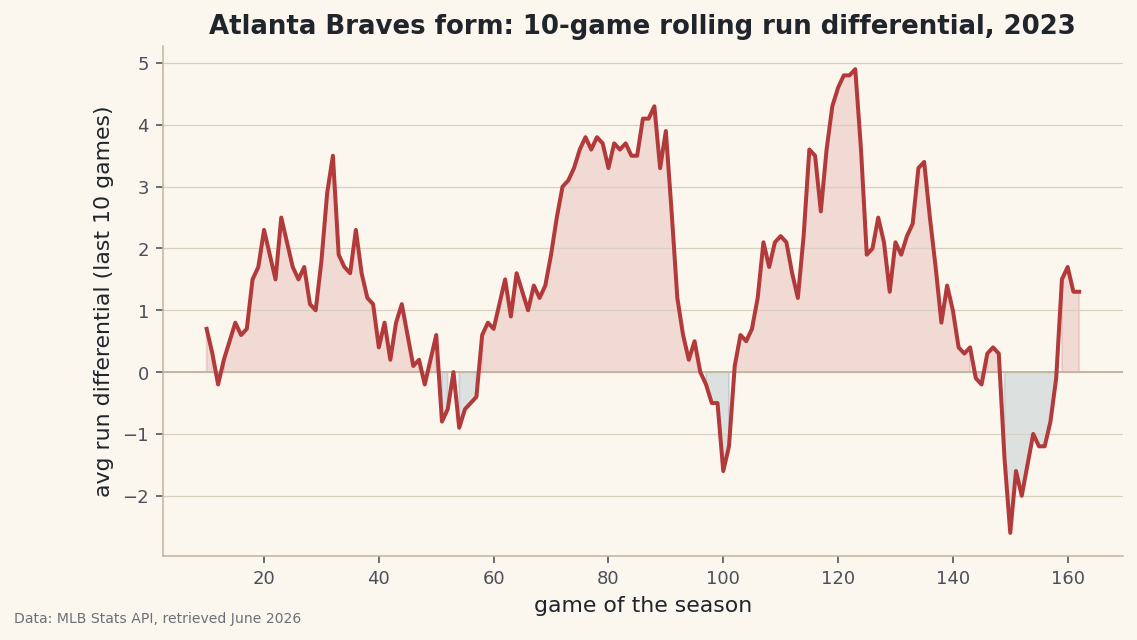
Pull a team's game log, sort by date, and use rolling windows and cumulative sums to measure form and momentum - the foundation of every 'hot streak' chart.
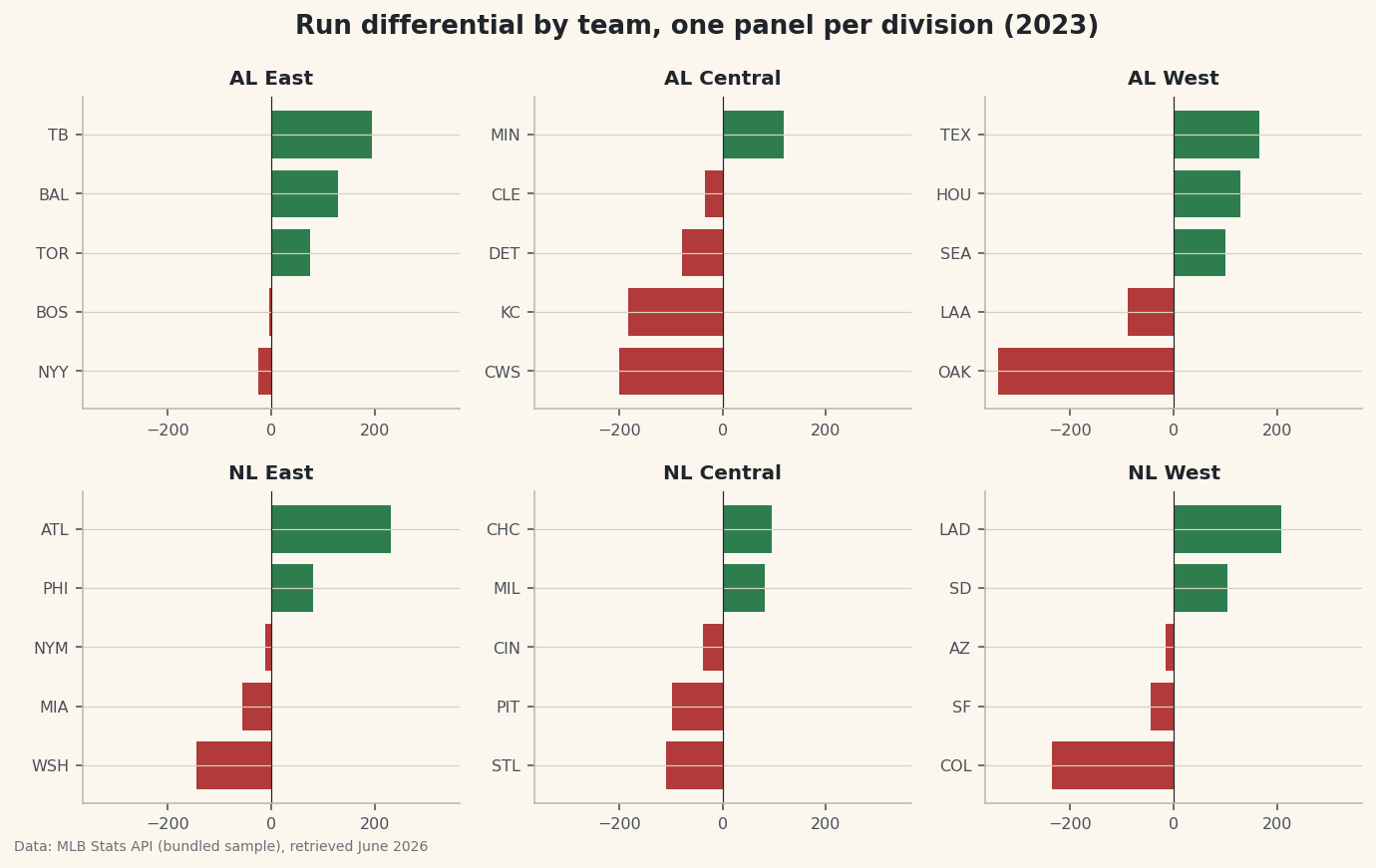
Learn matplotlib's subplots to build small multiples - a grid of tiny charts that share axes so you can compare many teams or groups at a single glance.
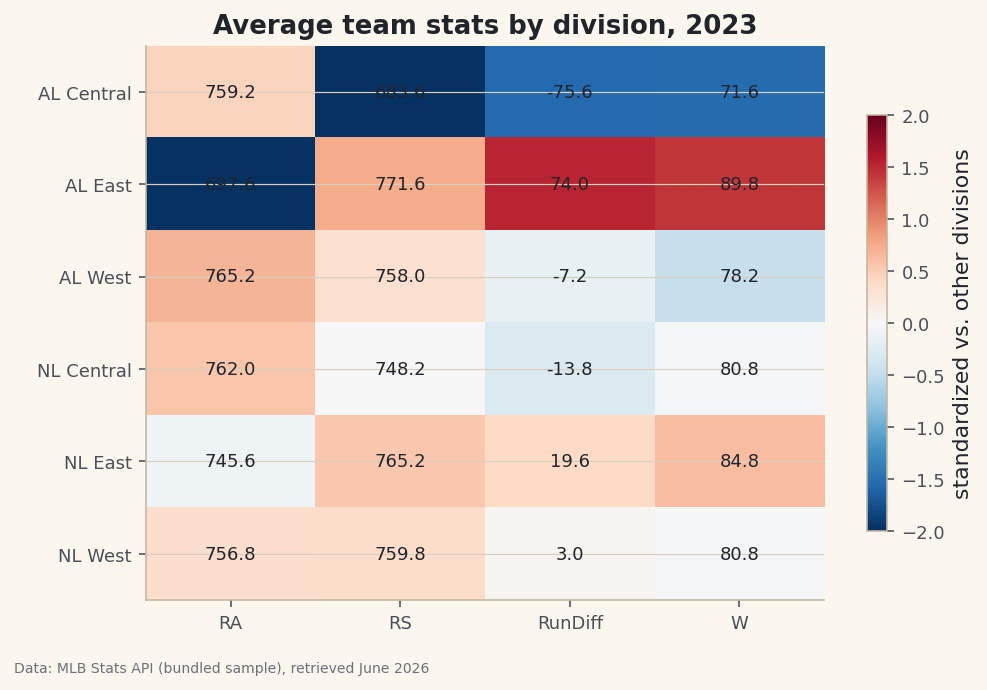
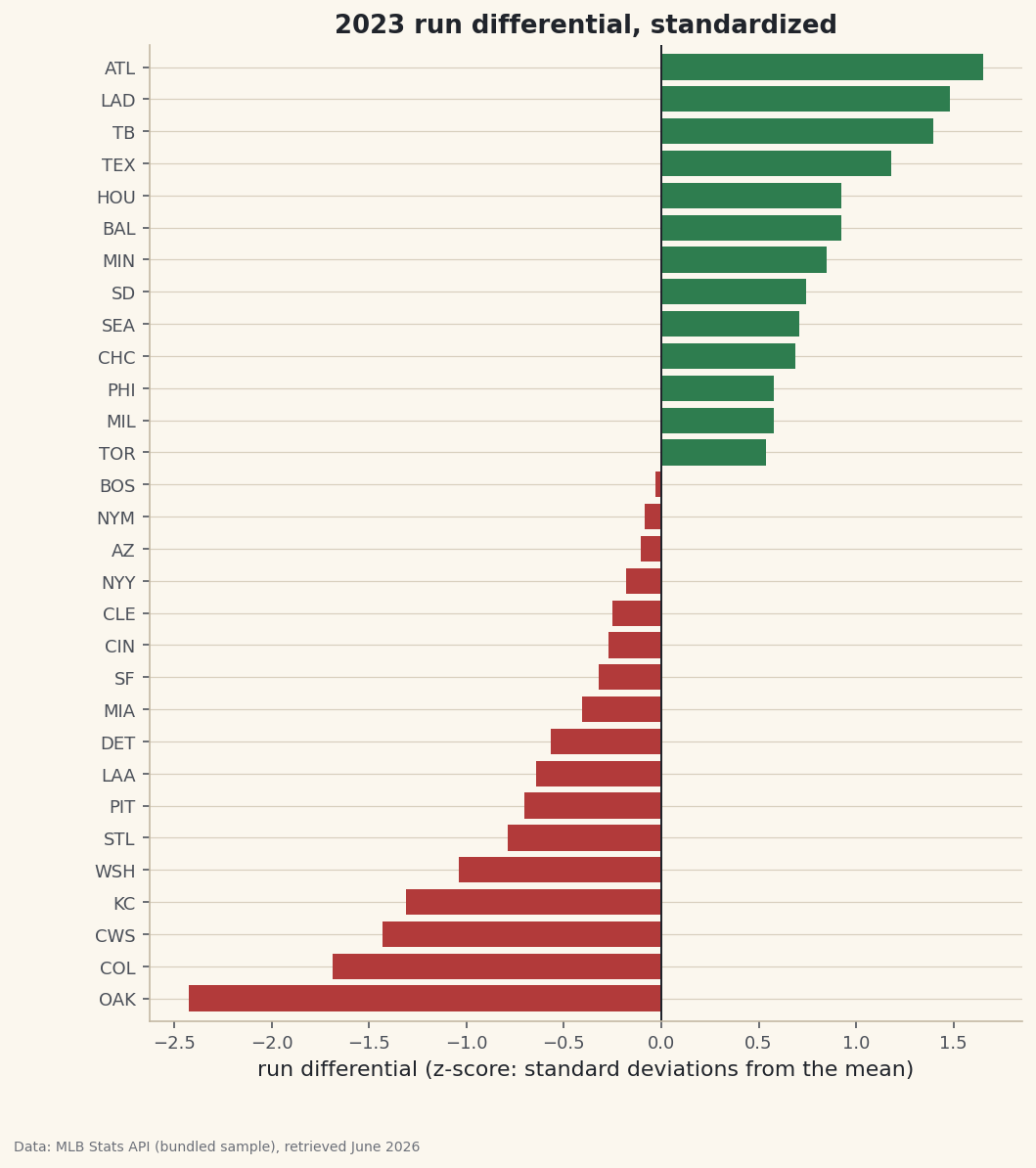
Convert runs scored, runs allowed, and run differential to z-scores so one number means the same thing in every column, then read a diverging bar chart.
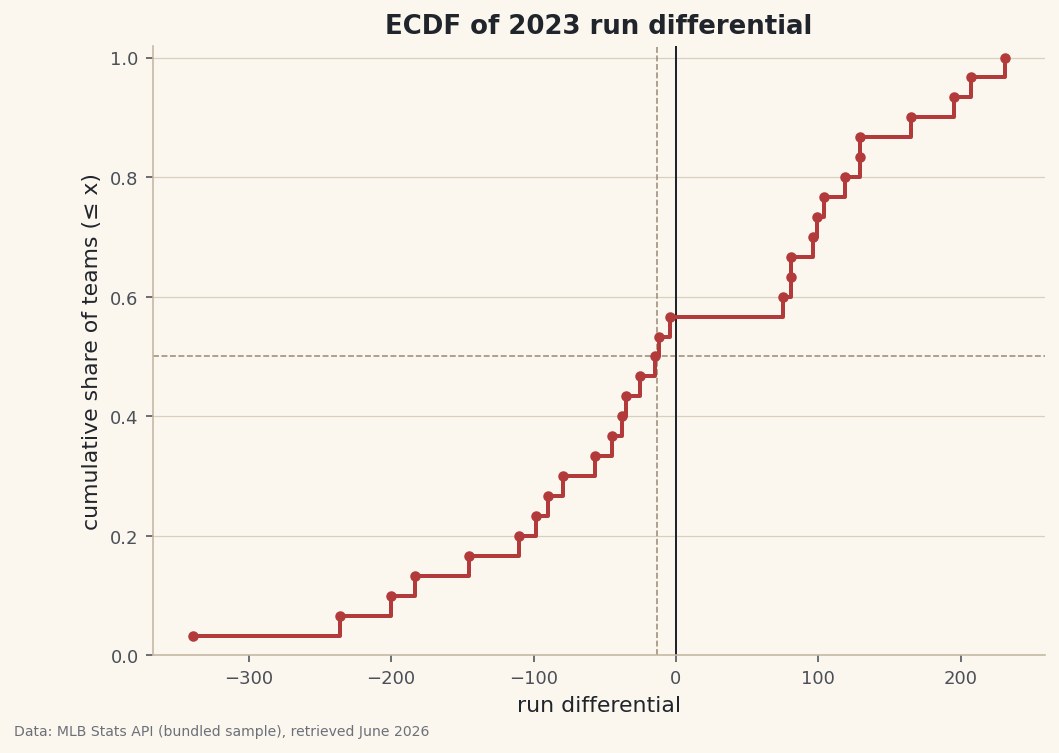
Where a histogram bins and smooths, the ECDF is exact: sort the values, assign each a running share, and read any percentile straight off the staircase.
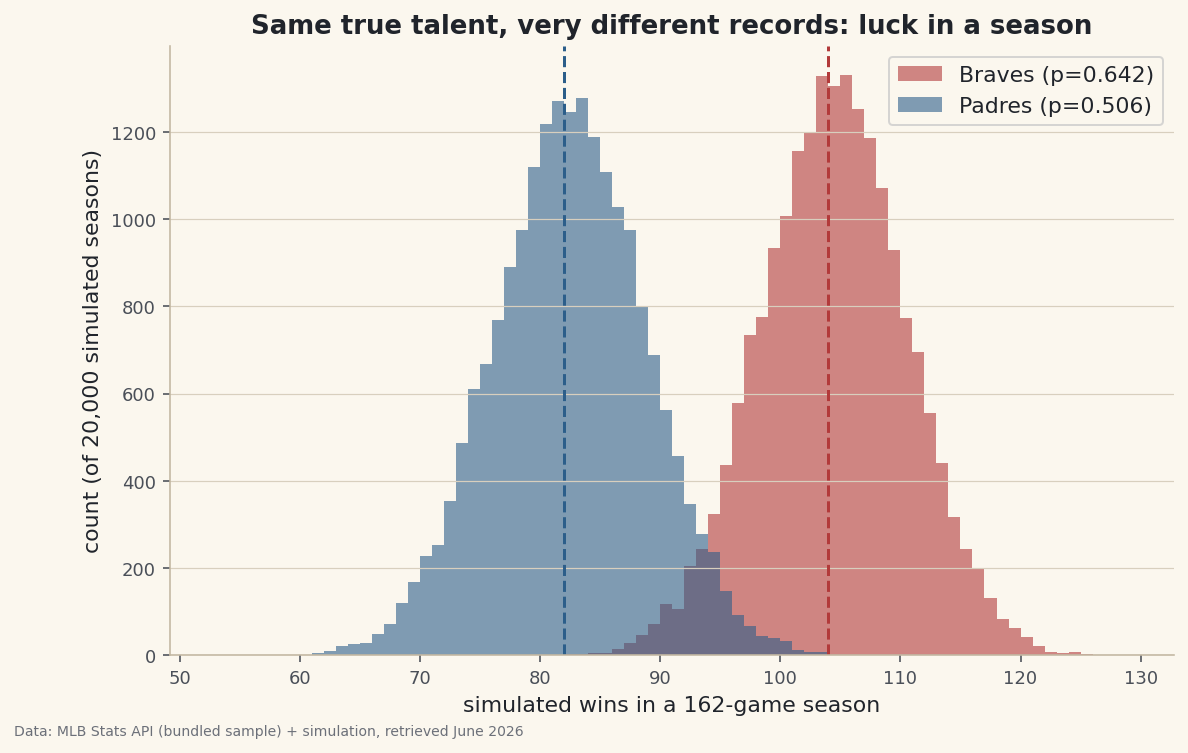
Treat a team's winning percentage as true talent, then simulate thousands of 162-game seasons with weighted coin flips. The spread is the luck in a record.
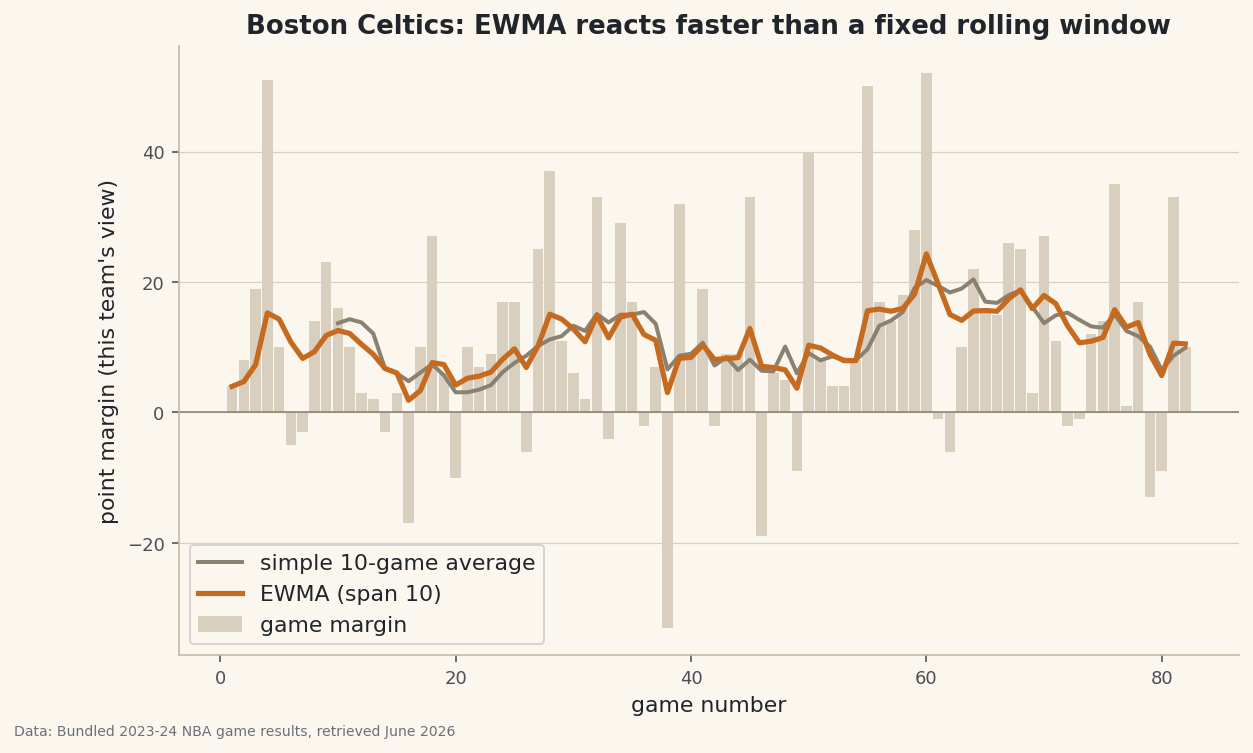
Smooth one NBA team's margin series two ways — a 10-game rolling mean versus pandas .ewm() — and watch the EWMA react faster to streaks without a hard window.
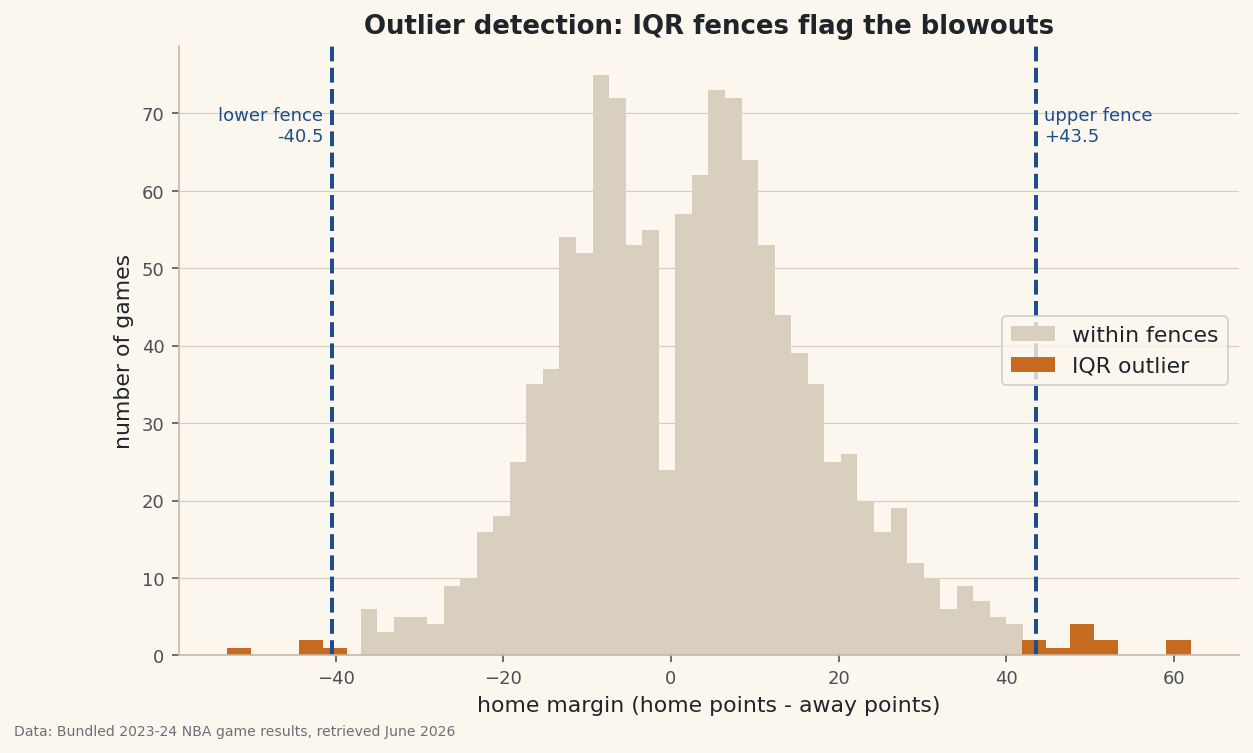
Flag blowouts in 1,231 real NBA margins three ways — IQR fences, the median/MAD modified z-score, and the fragile plain z-score — and see why robust wins.
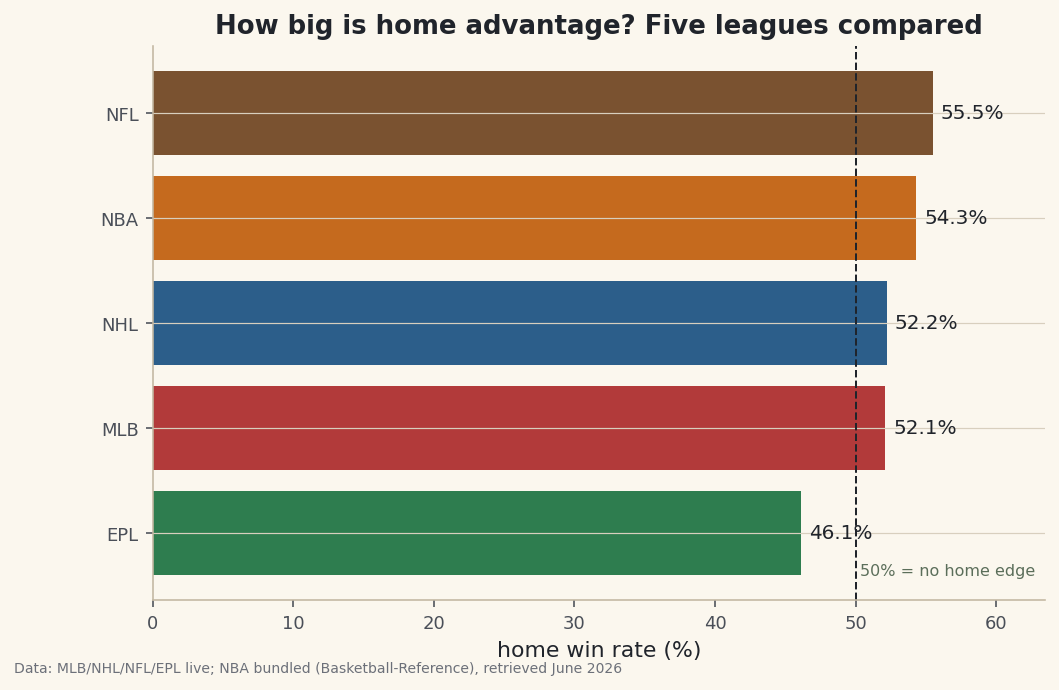
A capstone: ask one question - how big is home advantage? - across five leagues, reusing everything you've learned, and put the answers on a single comparison chart.
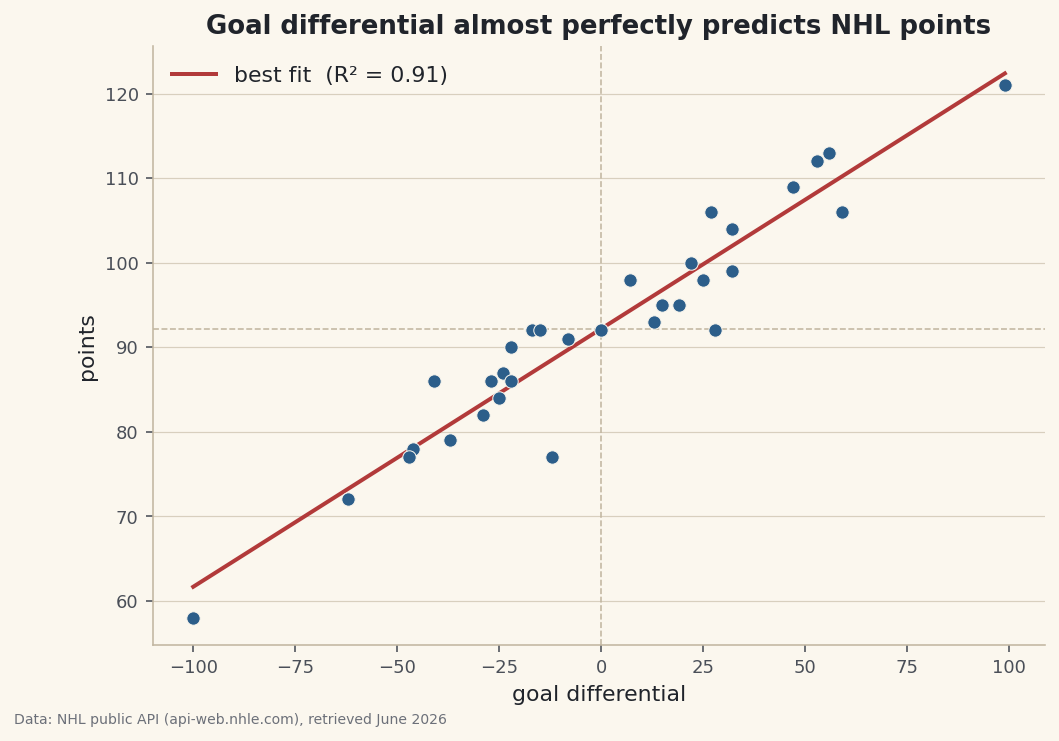
Quantify a relationship instead of eyeballing it: compute a correlation, fit a regression line with numpy, and report R-squared on NHL goal differential.
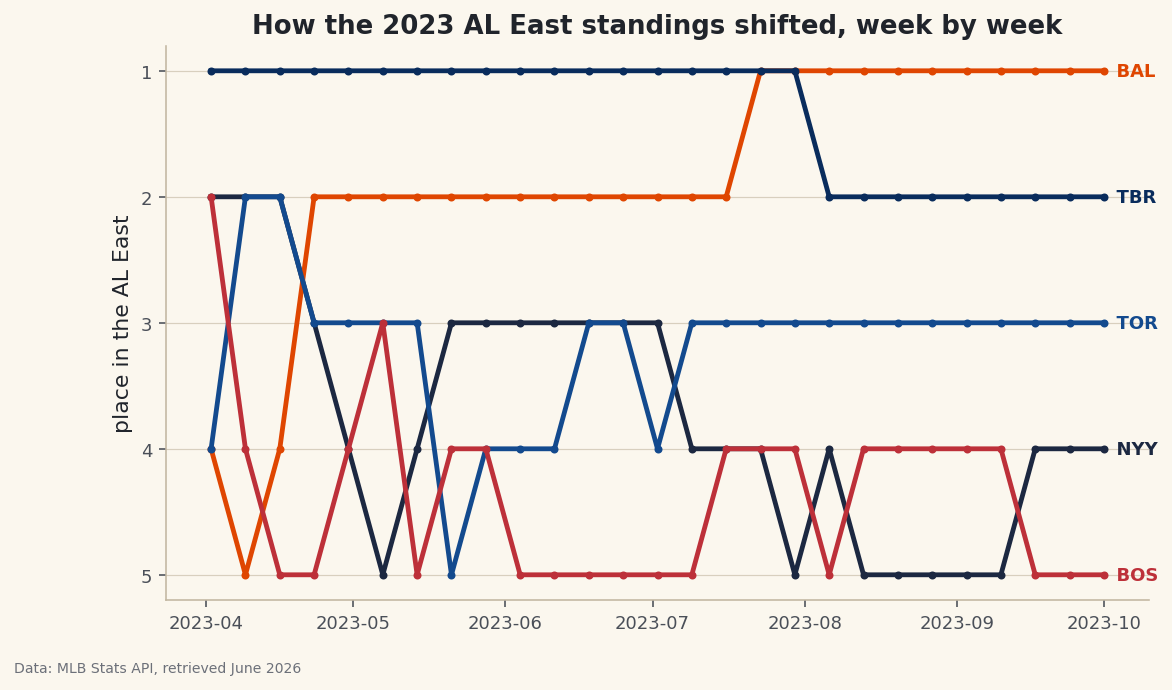
Reconstruct the standings week by week from a season of game results and draw a bump chart - the elegant ranked-line visual that shows every rise and fall.