Monte Carlo: How Much Does Luck Move a Season's Record?
Part 1 of 7 in Randomness, Inference & Simulation · course bundle (code + data)
What you'll build
Thousands of simulated 162-game seasons for two real teams, showing how far luck alone swings a record.
Here's a fact that should bother you a little: two teams with the exact same true talent can finish a season ten games apart in the standings, and neither did anything differently. That gap is luck. The way you measure it is Monte Carlo simulation — run the same random process thousands of times and look at the range of what comes out. It's the engine inside every playoff-odds model, and once you've built one, regression to the mean stops being a slogan and becomes arithmetic.
This builds on Summary Statistics and Distributions. For data we lean on sample_standings.csv again — the real 2023 MLB standings that ship with the site — so there's nothing to download first.
For the underlying statistics, read The Bootstrap and Simulation-Based Inference — a free DataField.dev chapter.
-
One season is a string of coin flips
Treat a team's winning percentage as its "true talent" — the probability it wins any given game. A 162-game season is then 162 weighted coin flips, and the win total is a draw from a binomial distribution. A fixed seed makes the whole thing reproducible.
python import numpy as np import pandas as pd df = pd.read_csv("sample_standings.csv") rng = np.random.default_rng(2026) # fixed seed -> same result every run best = df.loc[df["WinPct"].idxmax()] # the best team avg = df.loc[(df["WinPct"] - 0.5).abs().idxmin()] # a ~.500 team def simulate(p, games=162, trials=20000): return rng.binomial(games, p, size=trials) # one number = one season's winsThat's the whole model:
rng.binomial(162, p, 20000)plays twenty thousand seasons for a team of talentpand hands back twenty thousand final win totals. No loop needed — numpy vectorizes it. -
Read the spread, not the average
The mean of the simulations just recovers the talent you put in (162 × p). The interesting part is the spread — the 5th-to-95th-percentile range tells you how far a record can drift on luck alone.
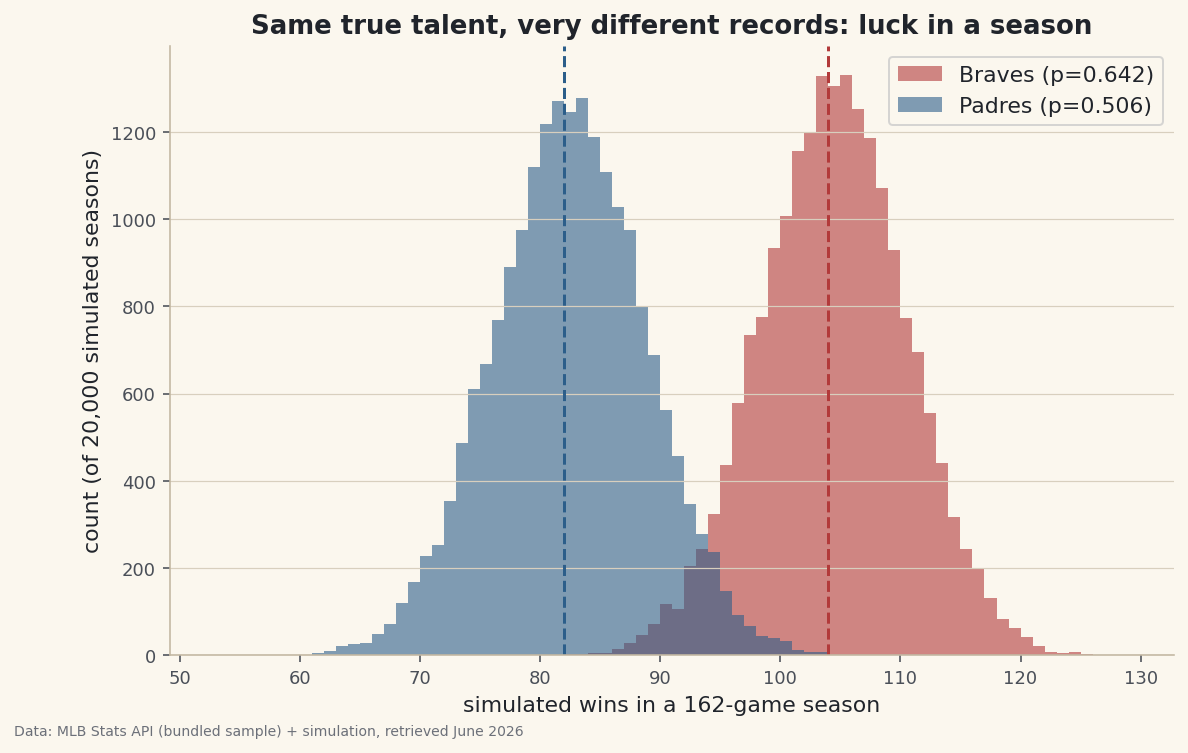
python for team, row in ((best["Team"], best), (avg["Team"], avg)): wins = simulate(row["WinPct"]) lo, hi = np.percentile(wins, [5, 95]) print(team, round(wins.mean(),1), "W, 90% range", int(lo), "-", int(hi))True talent in, a range of records outBraves true talent 0.642 -> mean 104.0 W, std 6.1, 90% range 94-114 (20 wins wide) Padres true talent 0.506 -> mean 82.0 W, std 6.4, 90% range 72-92 (20 wins wide) Same true talent, ~20-win spread: that gap is pure luck.
Look at the width: even with talent held perfectly fixed, the 90% range is about 20 wins wide. A team can be a true 90-win club and finish anywhere from the low 80s to 100 without the underlying quality changing at all. That is why a hot or cold record over a partial season tells you much less than it feels like it should.
-
Picture the luck
Histogram the simulated win totals for both teams on the same axis and the overlap makes the point no table can: the tails of a good team and an average team reach into each other's territory.
python import matplotlib.pyplot as plt fig, ax = plt.subplots(figsize=(9, 5.5)) for team, row, color in ((best["Team"], best, "#B23A3A"), (avg["Team"], avg, "#2C5E8A")): wins = simulate(row["WinPct"]) ax.hist(wins, bins=range(60, 120), alpha=0.6, color=color, label=team) ax.axvline(wins.mean(), color=color, ls="--") ax.set_xlabel("simulated wins"); ax.legend() fig.savefig("season_spread.png", dpi=144, bbox_inches="tight")Data: Bundled sample (2023 MLB standings) + simulation, retrieved June 2026 This same loop scales to anything you can assign a probability: simulate a full league of teams and count how often each makes the playoffs, and you've built a playoff-odds model. The honest version always reports the distribution, never a single confident number — because, as the chart shows, the single number was never the whole story.
Troubleshooting
My numbers change every run
You didn't seed the generator. Create it once with rng = np.random.default_rng(SEED) and reuse that rng; a fixed seed makes a simulation reproducible, which you want for a published chart.
Isn't winning percentage already polluted by luck?
Yes — using a team's actual record as its "true talent" overstates the talent of lucky teams. It's fine for showing the size of season-level variance, but a real projection would start from a regressed talent estimate (or a Pythagorean expectation), not the raw record.
How many trials do I need?
Enough that the answer stops moving. A few thousand is plenty for a mean; for tail probabilities (e.g. "odds of 100+ wins") push to tens of thousands. Re-run with different seeds and watch how much the estimate wobbles — that wobble is your Monte Carlo error.
Challenge yourself
Turn this into a one-number "luck" report: for every team in the file, simulate the season and compute the probability it wins at least as many games as its real record implies. Then build the playoff-odds version — assign each team a talent, simulate the whole league many times, and report how often each finishes in the top tier. Compare a seed-2026 run against seed-1 to see your Monte Carlo error.
Get the code
Here's the complete, working script for this tutorial. It runs exactly as shown.
Download the finished script (62_monte_carlo_season_simulation.py)This script imports a small shared helper (and reads any bundled sample data) that live next to it in /downloads/ — grab these into the same folder so it runs as-is: sdt_common.py. Or skip the collecting: the Randomness, Inference & Simulation bundle has this whole course’s scripts and data in one ZIP.