k-Nearest Neighbors From Scratch
What you'll build
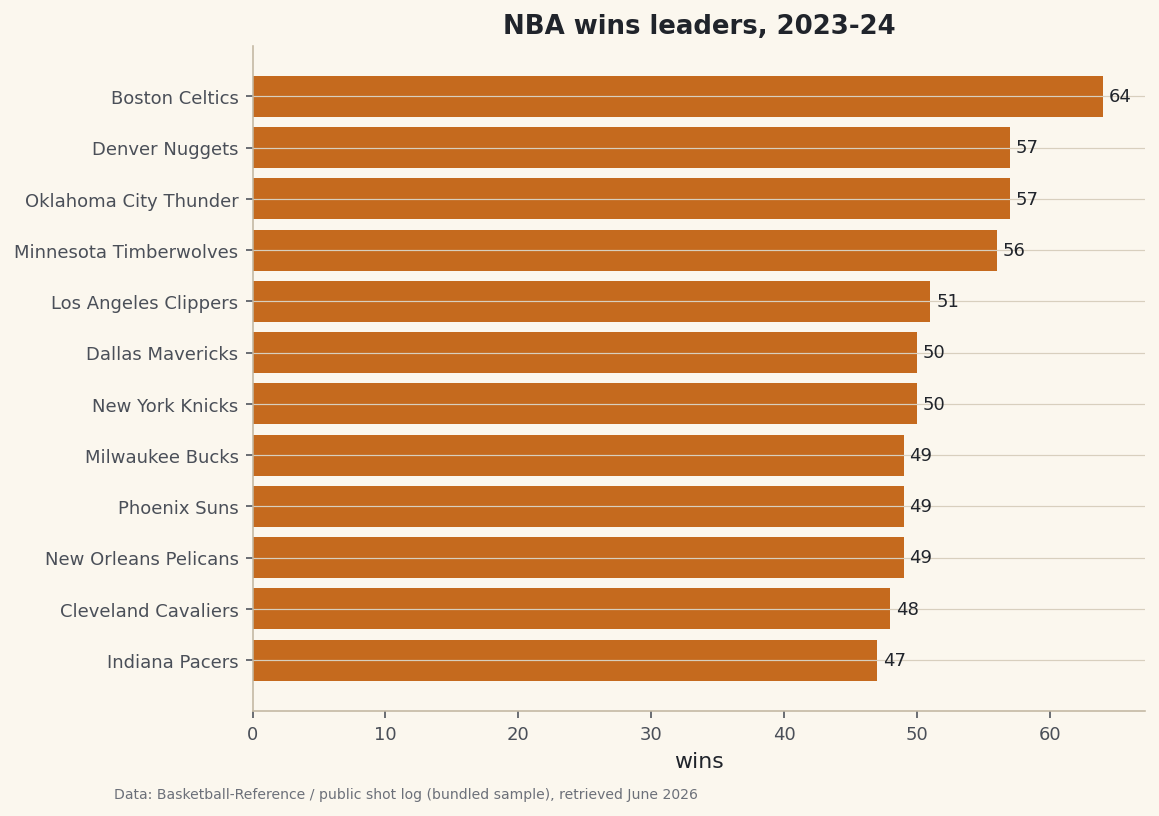
Build k-nearest neighbors from scratch in pure numpy - no training, just store the games and let the k closest ones vote - on a 2-D feature space (home and away net rating) to predict the NBA home win, then sweep k and compare to the tutorial-71 logistic regression.
Every classifier in this series so far — the logistic regression, and the models it set up in tutorials 72–74 — works by fitting: it tunes weights until a boundary fits the training data. k-nearest neighbors throws that idea out. It does no training at all. To predict a new game, it finds the k most similar past games and lets them vote. That's the whole algorithm, and building it from scratch is the fastest way to understand what “similar” really buys you.
We give it a 2-D feature space — the home team's net rating and the away team's net rating — predict the home win, and compare it to the tutorial-71 logistic regression on the same split. Bundled CSVs, pure numpy, offline.
Go deeper with the free textbook: Chapter 27: Logistic Regression and Classification at DataField.dev.
-
Build a 2-D feature space
Instead of collapsing the matchup to a single net-rating gap, we keep both teams' net ratings as two features. That gives k-NN a plane to measure distance in. We standardize both columns — k-NN uses raw distance, so a feature on a bigger scale would dominate the vote.
python import numpy as np, pandas as pd ratings = pd.read_csv("nba_ratings.csv") nrtg = dict(zip(ratings["Team"], ratings["NRtg"])) g = pd.read_csv("nba_home_results.csv") g = g[g["home_team"].isin(nrtg) & g["away_team"].isin(nrtg)].copy() g["home_nrtg"] = g["home_team"].map(nrtg) g["away_nrtg"] = g["away_team"].map(nrtg) g["home_win"] = (g["home_pts"] > g["away_pts"]).astype(int) X = g[["home_nrtg", "away_nrtg"]].to_numpy(float) y = g["home_win"].to_numpy() X = (X - X.mean(axis=0)) / X.std(axis=0) # standardize: distance needs equal scalesThen the usual 75/25 train/test split from tutorial 72, with a fixed seed so the result is reproducible.
-
The whole algorithm: distance, then a vote
There is no model to fit. For each game we want to predict, compute its distance to every training game, take the
kclosest, and average their labels — over 0.5 means “home win.” That's it.python def knn_predict(X_train, y_train, X_query, k): preds = np.empty(len(X_query), dtype=int) for i, q in enumerate(X_query): d = np.sqrt(((X_train - q) ** 2).sum(axis=1)) # distance to every train point nn = np.argsort(d)[:k] # the k closest preds[i] = int(round(y_train[nn].mean())) # majority vote return predsNo weights, no gradient descent, no training loop. The “model” is just the stored training set plus a choice of
k. -
Sweep k and read the result
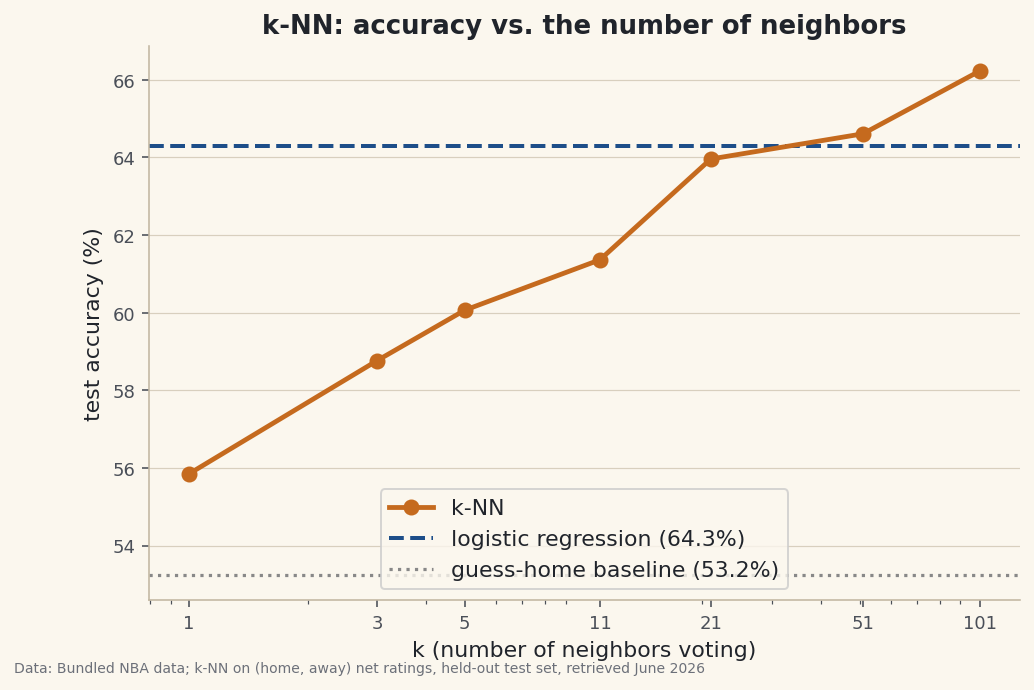
The one knob is
k. Too small and each prediction copies its single nearest game (it memorizes noise); too large and every game gets the same league-wide vote (it ignores the matchup). We try a range and score each on the held-out test set, against the tutorial-71 logistic regression and a guess-home baseline.k-NN accuracy by kTest games: 308 (home win rate 53.2%) Always-guess-home baseline: 53.2% k-NN accuracy by k: k= 1 : 55.8% k= 3 : 58.8% k= 5 : 60.1% k= 11 : 61.4% k= 21 : 64.0% k= 51 : 64.6% k=101 : 66.2% <- best Logistic regression (tutorial 71), same split: 64.3% Best k-NN (k=101): 66.2% Tiny k overfits (memorizes); huge k underfits (votes the whole league).
Data: Bundled Basketball-Reference net ratings + 1,231 game results; k-NN on (home, away) net ratings, held-out test set, retrieved June 2026 The pattern is the classic k-NN trade-off. At k=1 accuracy is just 55.8% — barely above the 53.2% you'd get by always picking the home team — because a single neighbor is pure noise. As
kgrows the vote steadies: 60.1% at k=5, 64.0% at k=21, up to 66.2% at k=101, the best here. For comparison, the tutorial-71 logistic regression scores 64.3% on the same split. A model that does no training at all lands right alongside one that does — because the signal in two net ratings is simple and roughly linear, exactly the kind of problem where a big-kvote and a fitted line agree. -
Why bigger k wins here (and where it wouldn't)
This data is noisy and its real boundary is smooth, so heavy smoothing — a large
k— helps. That is not a universal law. On data with a twisty, local boundary, a largekwould blur away the very structure you need, and a smallkwould win. The honest takeaway is thatkis a dial you tune per problem, ideally with the cross-validation from tutorial 73 rather than by eyeballing a test set. k-NN's appeal is that it makes no assumption about the shape of the boundary at all; its cost is that it stores every training row and recomputes every distance at prediction time.
Troubleshooting
My accuracy is worst at k=1
That's expected, not a bug. k=1 copies the label of the single closest game, so it fits the training set perfectly and generalizes poorly — the textbook sign of overfitting. Accuracy should climb as k increases, then eventually sag back toward the baseline as k approaches the whole training set.
I forgot to standardize and the results got worse
k-NN measures raw Euclidean distance, so if one feature spans a far wider range it silently dominates every distance. Both net-rating columns are on a similar scale here, so the effect is mild — but standardizing (subtract mean, divide by SD) is the safe habit, and essential when features use different units.
Should I use an even or odd k?
For two classes, an odd k avoids tie votes. Our code rounds a 0.5 average up to 1 (home win), which breaks ties deterministically, so even k still runs — but odd values keep the vote unambiguous.
Challenge yourself
Pick k the right way: wrap the accuracy check in the 5-fold cross-validation from tutorial 73 and choose the k with the best cross-validated score instead of the best test score. Then add a third feature (rest days, or home-team pace) and see whether the extra dimension helps or just adds noise — k-NN gets harder in higher dimensions, the “curse of dimensionality.” Finally, weight each neighbor's vote by 1/distance so closer games count more, and see if it beats the plain majority.
Get the code
Here's the complete, working script for this tutorial. It runs exactly as shown.
Download the finished script (75_k_nearest_neighbors.py)This script imports a small shared helper (and reads any bundled sample data) that live next to it in /downloads/ — grab these into the same folder so it runs as-is: sdt_common.py, sdt_nba.py.