Gradient Descent From Scratch: How Models Actually Learn
What you'll build
A pure-numpy gradient descent that learns the run-differential-to-wins line by stepping downhill on the error surface, with a loss curve and the fitted line - landing on the exact closed-form answer.
Back in the regression tutorial we fit a line with a one-shot formula. That's a luxury — most machine-learning models have no closed-form answer and have to learn it instead, by starting with a bad guess and nudging it downhill until the error stops shrinking. That process is gradient descent, and it's the engine under almost every model you'll meet. We'll build it from scratch in pure numpy, watch the loss fall step by step, and confirm it arrives at the exact same line the formula gives.
This builds on Z-Scores (we standardize so one learning rate works) and pairs with k-means (another algorithm that loops to a solution). The data is the bundled sample_standings.csv (real 2023 MLB standings), so it runs offline.
Go deeper with the free textbook: Linear Regression: Your First Predictive Model at DataField.dev.
-
Set up the problem
We'll learn the line from run differential to wins. Standardize both to z-scores first — that puts them on a common scale so a single learning rate behaves, and it's a habit worth keeping for gradient descent.
python import numpy as np, pandas as pd df = pd.read_csv("sample_standings.csv") x = ((df.RunDiff - df.RunDiff.mean()) / df.RunDiff.std()).to_numpy() y = ((df.W - df.W.mean()) / df.W.std()).to_numpy() m, b = 0.0, 0.0 # start with a flat line: slope 0, intercept 0The descent, start to finishStart loss: 0.9667 After 200 steps: 0.1056 Learned slope m = 0.944, intercept b = -0.000 Closed-form (numpy.polyfit): slope 0.944, intercept 0.000 Gradient descent landed on the same line - it just walked there.
-
The idea: roll downhill on the error surface
Pick a loss — mean squared error, the average squared gap between prediction and truth. For any line
(m, b)the loss is some height on a bowl-shaped surface. Gradient descent computes the slope of that bowl (the gradient) and steps in the downhill direction. Do it enough times and you reach the bottom: the best-fit line.python lr = 0.1 # learning rate: how big each step is losses = [] for step in range(200): pred = m * x + b err = pred - y losses.append(np.mean(err ** 2)) # current loss dm = 2 * np.mean(err * x) # gradient w.r.t. slope db = 2 * np.mean(err) # gradient w.r.t. intercept m -= lr * dm # step downhill b -= lr * dbThat's the whole algorithm: predict, measure the error, compute the two gradients, take a small step against them, repeat. No formula for the answer — just thousands of tiny corrections.
-
Watch the loss fall
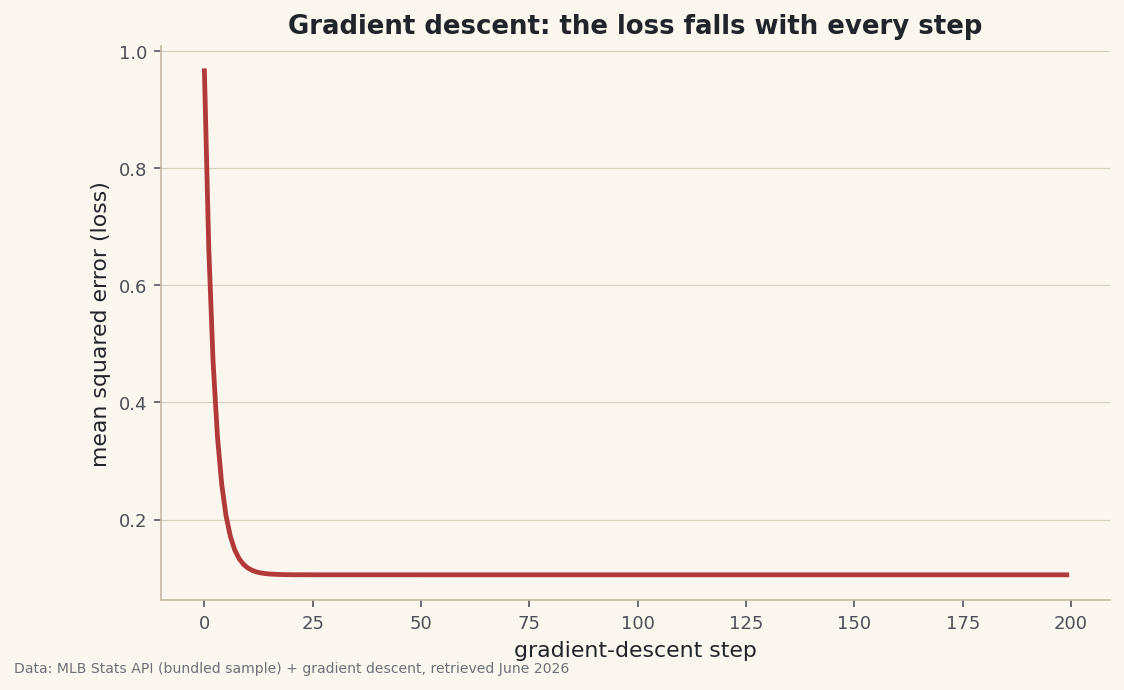
The single most useful plot in machine learning is the loss curve: error against training step. A healthy run drops fast, then flattens as it nears the bottom.
python import matplotlib.pyplot as plt fig, ax = plt.subplots() ax.plot(losses) ax.set_xlabel("step"); ax.set_ylabel("mean squared error") fig.savefig("gd_loss.png", dpi=144, bbox_inches="tight")Data: Bundled sample (real 2023 MLB standings) + gradient descent, retrieved June 2026 Ours drops from 0.97 to 0.11 and levels off — the line has stopped improving. That flattening is how you know to stop training.
-
Confirm it learned the right line
Gradient descent isn't magic — for a straight line it should land exactly where the closed-form formula does. It does: a learned slope of 0.944, matching
numpy.polyfitto three decimals. It just walked there instead of solving it in one step.python fig, ax = plt.subplots() ax.scatter(x, y) xs = np.linspace(x.min(), x.max(), 50) ax.plot(xs, m * xs + b) # the learned line fig.savefig("gd_fit.png", dpi=144, bbox_inches="tight")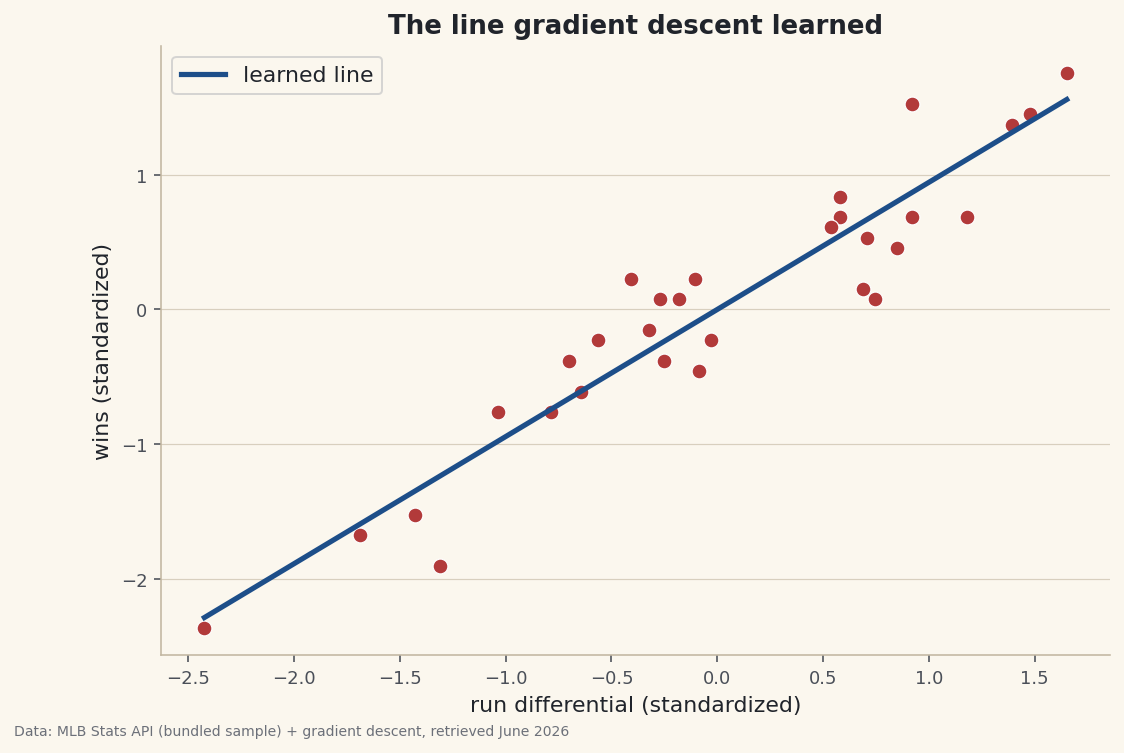
Data: Bundled sample (real 2023 MLB standings) + gradient descent, retrieved June 2026 The payoff: this same loop fits models that have no formula — logistic regression, neural networks, everything. Swap the prediction and the loss; the predict-measure-step-repeat skeleton never changes.
Troubleshooting
My loss explodes to infinity
Your learning rate is too big — the steps overshoot the bottom and bounce up the other side, worse each time. Lower lr (try 0.01) or standardize your inputs (we did), which keeps the gradients well-scaled.
The loss barely moves
The opposite: the learning rate is too small, so it inches along. Raise it, or run more steps. The loss curve tells you which problem you have — exploding (too big) vs. crawling (too small).
Why standardize if polyfit doesn't need it?
The closed-form solution is scale-invariant; gradient descent isn't. Wildly different feature scales make the error bowl long and skinny, and a single learning rate can't handle both directions. Standardizing makes the bowl round and the descent smooth. To recover real-world units, multiply the standardized slope back by the ratio of the SDs.
Challenge yourself
Record m and b every few steps and plot the line slowly rotating into place over the scatter — a great animation of learning. Then try three learning rates (0.001, 0.1, 1.5) on one loss-curve plot to see crawling, healthy, and exploding side by side. Finally, extend the loop to two features (run differential and something else) — the gradient just gains one more component.
Get the code
Here's the complete, working script for this tutorial. It runs exactly as shown.
Download the finished script (70_gradient_descent_from_scratch.py)This script imports a small shared helper (and reads any bundled sample data) that live next to it in /downloads/ — grab these into the same folder so it runs as-is: sdt_common.py.